
Dena Bazazian is a lecturer (assistant professor) in machine vision and robotics at the University of Plymouth. Previously, she was a senior research associate at the Visual Information Laboratory of the University of Bristol. Prior to that, she was a research scientist at CTTC (Centre Tecnològic de Telecomunicacions de Catalunya)
and a postdoctoral researcher at the Computer Vision Center (CVC), Universitat Autònoma de Barcelona (UAB) where she accomplished her PhD in 2018.
She had long-term research visits at NAVER LABS Europe in Grenoble, France in 2019 and at the Media Integration and Communication Center (MICC), University of Florence, Italy in 2017. She was working with the Image Processing Group (GPI) at Universitat Politècnica de Catalunya (UPC) between 2013 and 2015.
Dena Bazazian was one of the main organizers of the series of Deep Learning for Geometric Computing (DLGC) workshops at CVPR2024-20, ICCV2021, Women in Computer Vision (WiCV) Workshops at CVPR2018 and ECCV2018, Robust Reading Challenge on Omnidirectional Video at ICDAR2017.
Research
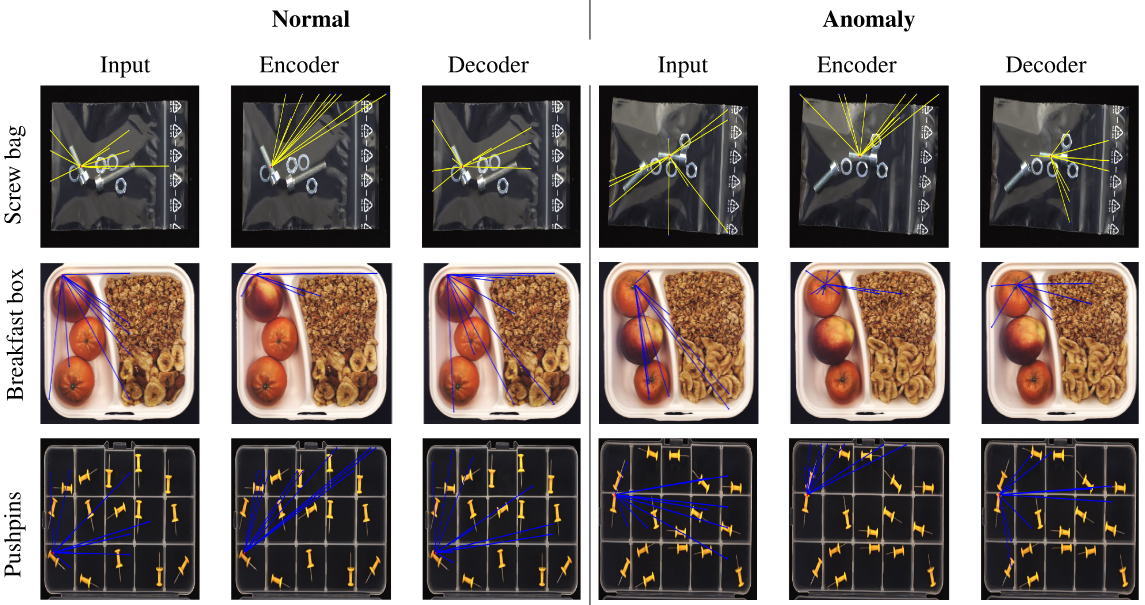
Zoghlami, D., Bazazian, D. , Masala, G., Gianni, M., Khan, A.
IEEE Access, 2024.
title={ViGLAD: Vision Graph Neural Networks for Logical Anomaly Detection},
author={Zoghlami, Firas and Bazazian, Dena and Masala, Giovanni and Gianni, Mario and Khan, Asiya},
journal={IEEE Access},
publisher={IEEE},
year={2024}
}
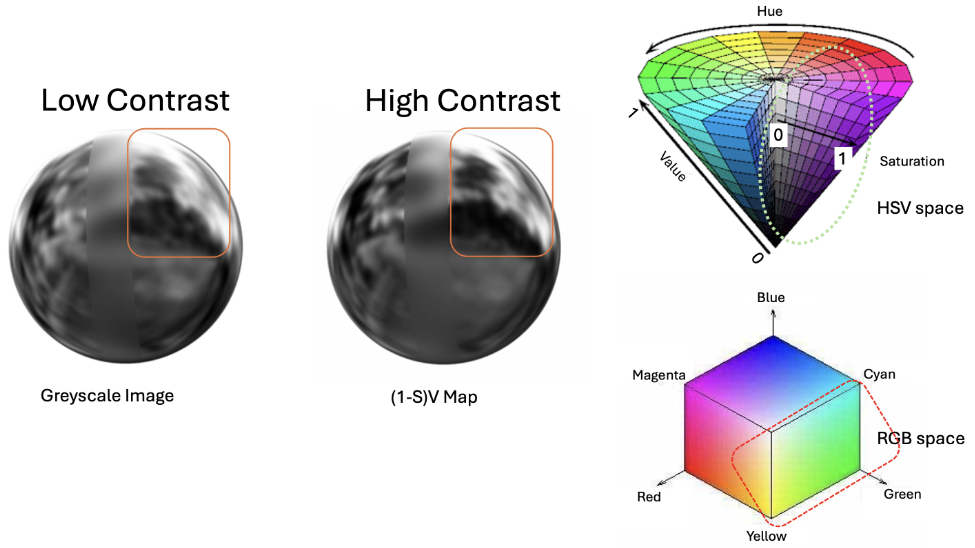
Selvaratnam, D., Bazazian, D.
CVPR w, 2024.
title={Localised-NeRF: Specular Highlights and Colour Gradient Localising in NeRF},
author={Selvaratnam, Dharmendra and Bazazian, Dena},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={2791--2801},
year={2024}
}
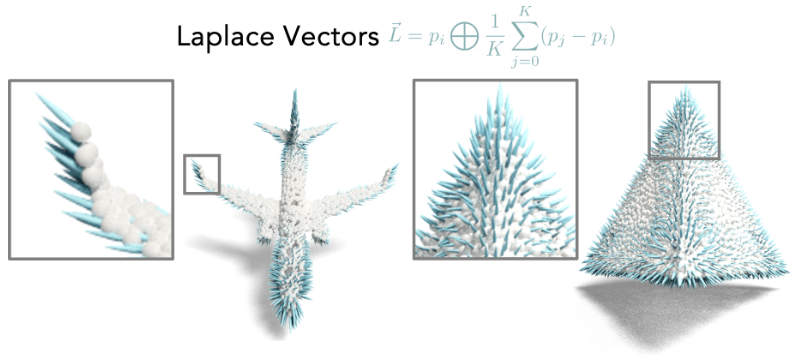
Anvekar, T., Bazazian, D.
CVPR w, 2023.
title={Gpr-net: Geometric prototypical network for point cloud few-shot learning},
author={Anvekar, Tejas and Bazazian, Dena},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={4178--4187},
year={2023}
}

Bazazian, D. , Magland, B., Grimm, C., Chambers, E., Leonard, K.
The Visual Computer Journal, 2022.
author={D. {Bazazian} and B. {Magland} and C. {Grimm} and E. {Chambers} and K. {Leonard} },
journal={The Visual Computer},
title={Perceptually grounded quantification of 2D shape complexity},
year={2022},
volume={38},
pages={3351–3363},
doi={https://doi.org/10.1007/s00371-022-02634-8}}
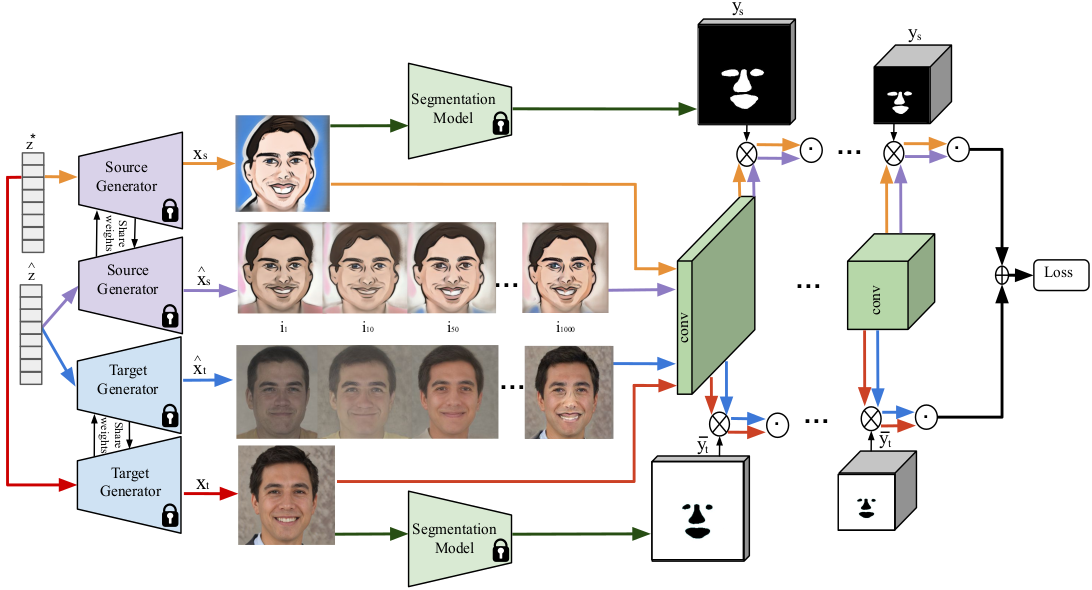
Bazazian, D. , Calway, A., Damen, D.
CVPR w, 2022.
author={Bazazian, Dena and Calway, Andrew and Damen, Dima},
journal={IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)},
title={Dual-Domain Image Synthesis using Segmentation-Guided GAN},
year={2022},
pages={1-16},
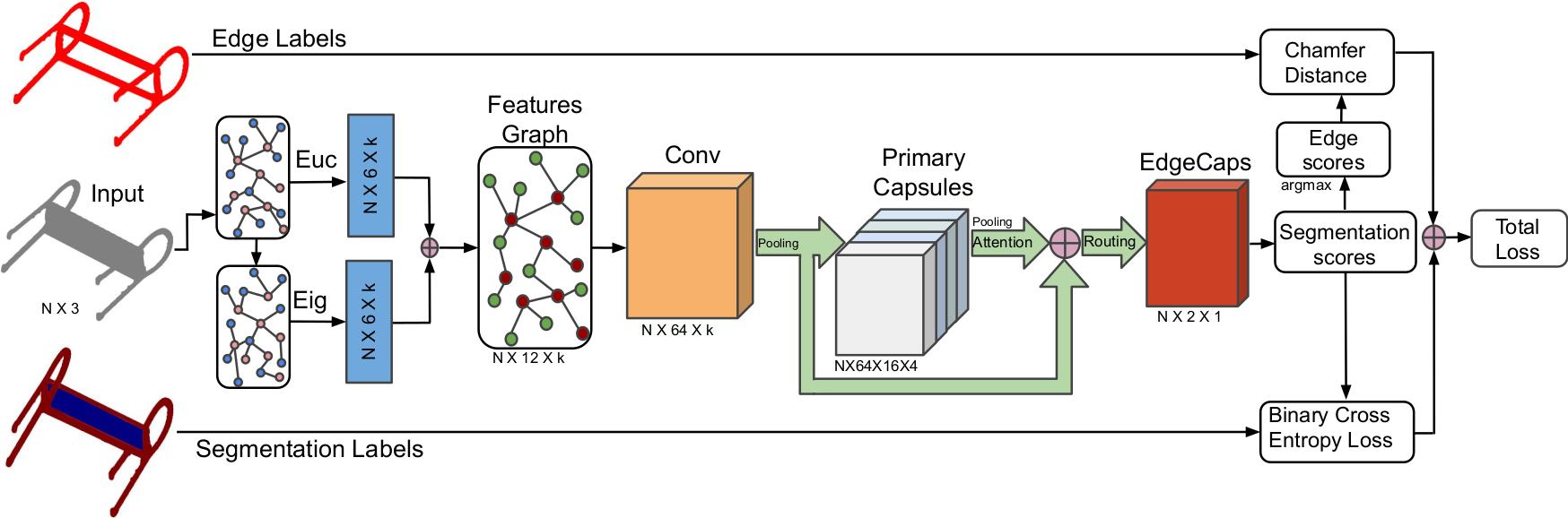
Bazazian, D. , Parés, ME.
Applied Sciences Journal, 2021.
author={D. {Bazazian} and ME. {Parés}},
journal={Applied Sciences},
title={EDC-Net: Edge Detection Capsule Network for 3D Point Clouds},
year={2021},
volume={11},
number={4: 1833},
pages={1-16},
doi={https://doi.org/10.3390/app11041833}}
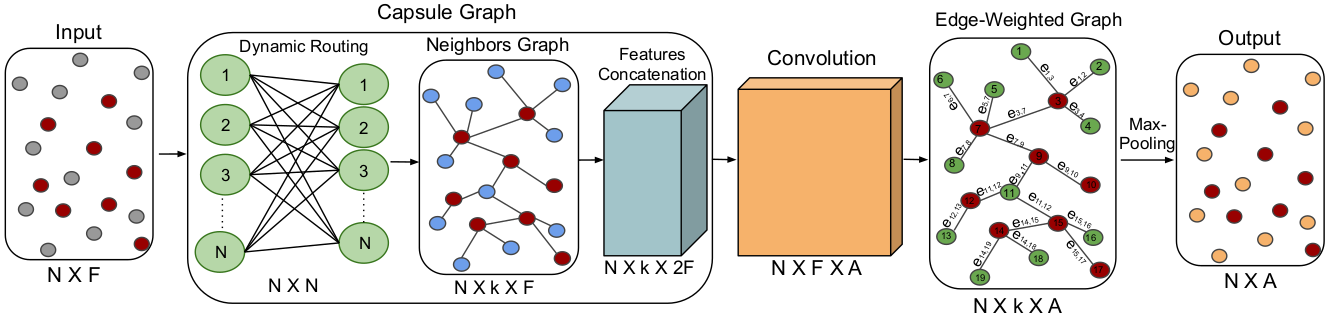
Bazazian, D. , Nahat, D.
IEEEAccess Journal, 2020.
author={D. {Bazazian} and D. {Nahata}},
journal={IEEE Access},
title={DCG-Net: Dynamic Capsule Graph Convolutional Network for Point Clouds},
year={2020},
volume={8},
number={},
pages={188056-188067},
doi={10.1109/ACCESS.2020.3031812}}

Al-Rawi, M., Bazazian, D., Valveny, E.
ICCV w, 2019.
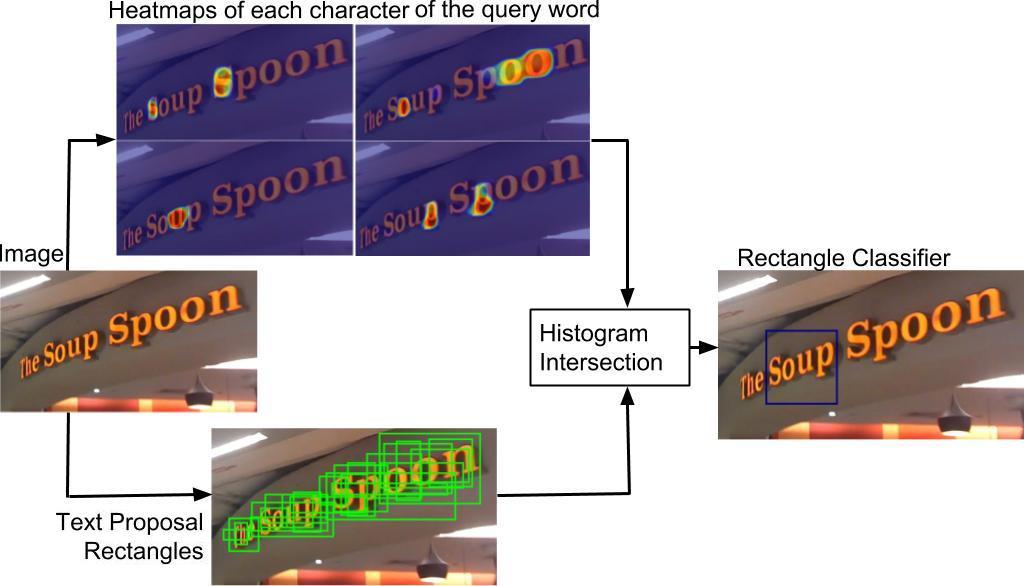
Bazazian, D., Karatzas, D. and Bagdanov, A.
CVPR w, 2018.
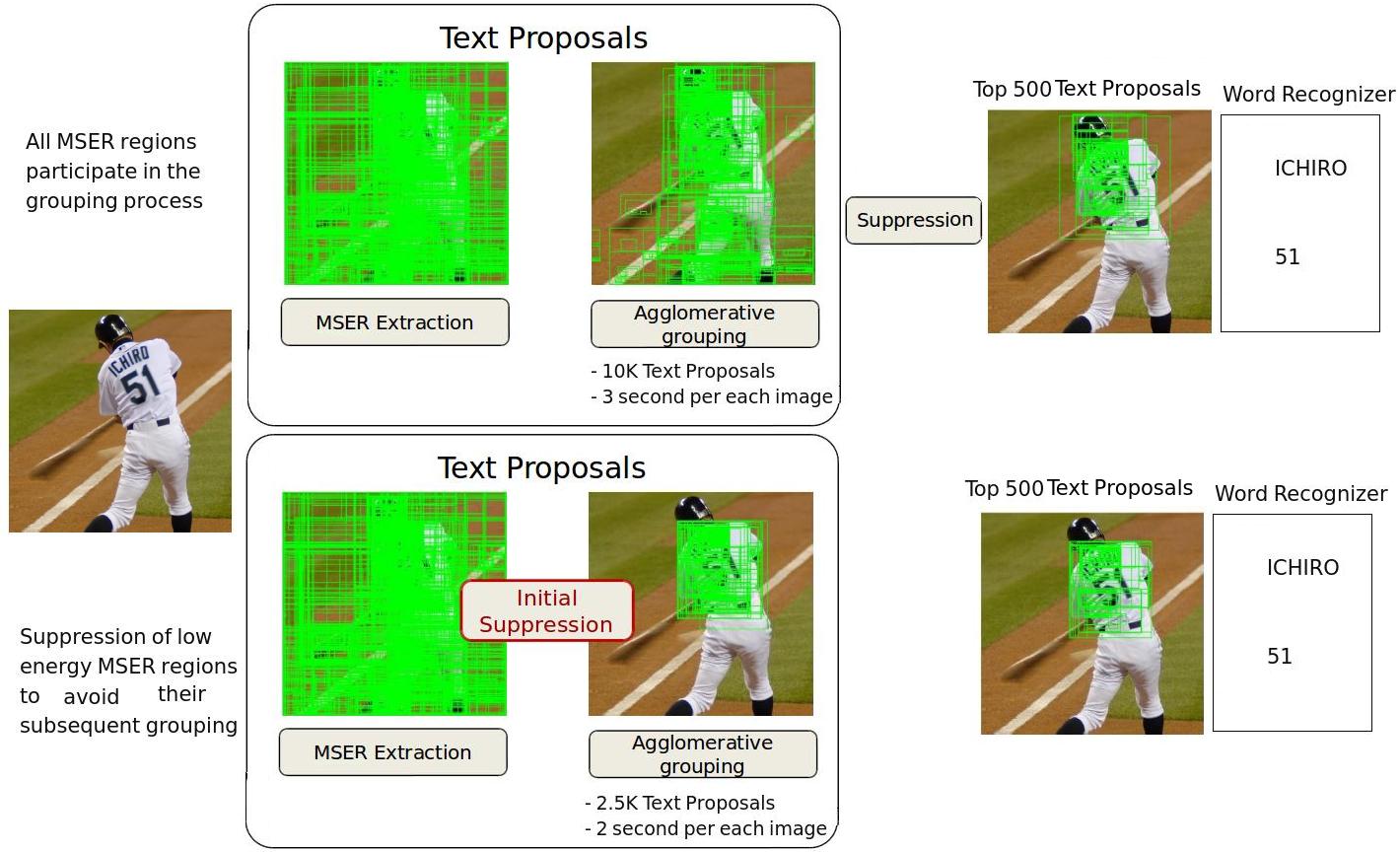
Bazazian, D., Gomez, R., Gomez, L., Nicolaou, A., Karatzas, D., and Bagdanov, A.
Pattern Recognition Letter (PRL) Journal, 2017.

Galteri, L., Bazazian, D., Seidenari, L., Bertini, M., Bagdanov, A., Nicolaou, A., Karatzas, D.
ICCV w, 2017.
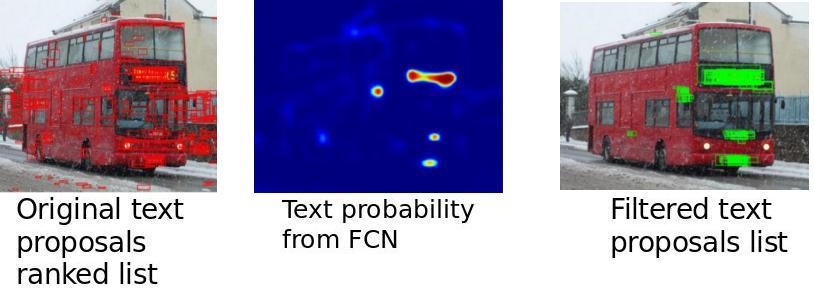
Bazazian, D., Gomez, R., Gomez, L., Nicolaou, A., Karatzas, D., and Bagdanov, A.
ICPR, 2016.

Iwamura, M., Morimoto, N., Tainaka, K., Bazazian, D., Gomez, L., Karatzas, D.
ICDAR, 2017.
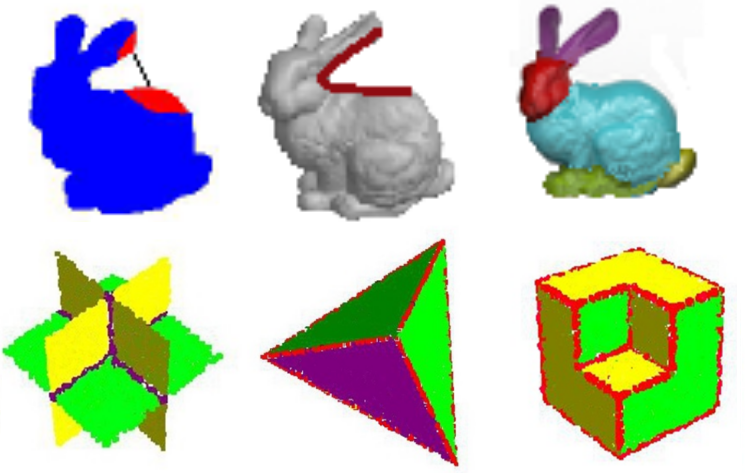
Bazazian, D., , Casas, J.R., Ruiz-Hidalgo, J.
VISAPP, 2017.

Bazazian, D., , Casas, J.R., Ruiz-Hidalgo, J.
DICTA, 2015.